2022-06-27 来源: 《银行家》2022年第5期
作者:吴永飞 等
2022年1月16日,习近平总书记发表署名文章《不断做强做优做大我国数字经济》,指出数字经济正在成为重组全球要素资源、重塑全球经济结构、改变全球竞争格局的关键力量。一直以来,党和国家高度重视发展数字技术、数字经济。作为数字经济的有机组成部分,数字金融是数字经济时代实体企业蓬勃发展的助推器。数字经济与数字金融的发展并没有改变经济与金融之间的关系本质,而是通过运用现代信息技术和新兴数字技术,有效提高了经济与金融活动的效率、降低了成本、防范了风险。数字金融的内涵是金融行业及相关产业的数字化转型发展;其外延随着数字经济的发展,逐渐聚焦形成消费数字金融、普惠数字金融和产业数字金融三种主要业态。通过对消费经济、普惠经济和产业经济进行数字化转型升级,并以数字技术作为沟通衔接,与数字金融有机结合起来,形成经济与金融高质量、高效率发展的良性循环,全面推动数字经济时代社会经济的蓬勃发展。
产业数字化是数字经济发展的重要方向之一,而产业数字金融则是产业数字化、数字经济规模化发展的加速器。金融永远不变的核心本质是风控,其实质是运用现代数字技术将数据算料通过算力、算法等新型基础设施平台加工成智能风控模型,从而降低由业务参与各方信息不对称造成的业务不确定性。然而,产业数字金融风控所使用的数据要素情况不同于以往,特别是对公客户场景化、生态化细分后,数据样本量很小,难以满足风控建模的需要;而小样本学习目前在机器学习与数据挖掘领域仍属世界性难题。本文从小样本学习技术创新入手,深入探索数字经济时代下面向产业数字金融的小样本学习应用研究与实践。
面向金融风控领域的机器学习算法模型
传统的商业银行风控体系以定性风险管理为主,主要使用风控规则及客户评级等方法,辅以线下尽调的方法;传统风控模型对包含客户历史行为和相关活动的数据进行分析,但难以预测性地揭示未来风险的变化情况,且数据获取方式单一、定量分析结果相对较弱。数字经济时代下面向数字金融发展,商业银行越来越强调运用金融科技力量来降低风险管理成本、提升客户体验,以数据驱动风控能效的提升,以人工智能算法为基础建立智能风控评价体系。
在商业银行风控场景中,往往会选用一些效果佳、业务可解释性强的有监督学习分类算法来构建风控模型,如逻辑回归、决策树以及集成算法等。通过内外部数据融合、数据预处理、特征工程等方法进行数据准备,并根据场景需求及业务数据特点,选择合适的算法开展分析建模,并进行模型的部署和监测。
逻辑回归(Logistic Regression)常用于二分类问题,其原理源于线性回归,运用Sigmoid函数把线性回归的结果(-∞,∞)映射到(0,1)之间。逻辑回归因其业务可解释性较强、计算速度较快、对线性关系的拟合效果较优、上线便捷、方便管理等特点被广泛应用于银行场景的二分类任务中,尤其是银行风控领域。
决策树(Decision Tree)利用其类似于树杈的模型结构,通过对一系列问题进行“是/否”的推导,最终以结构图的方式来解决决策问题。在多数情况中,决策树有一个根节点、多个内部节点和多个叶节点,因其从“树根”到“树叶”可以形成多条分类规则,模型可解释性强,同时分类准确性往往较优、模型应用便捷,因而决策树算法被广泛应用于金融风控建模中。
集成算法(Ensemble Algorithm)通过组合多个简单算法形成累积效果,这种方法得到的模型准确性往往更高,可谓“博采众长”,但模型训练时间较长、模型可解释性弱。集成算法的思想主要分为三种:装袋算法(Bagging,亦称为Bootstrap Aggregating,引导聚集算法)、提升算法(Boosting)和堆叠算法(Stacking)。基于Bagging思想的代表性算法为随机森林(Random Forest),以及基于Boosting思想的代表性算法为XGBoost和LightGBM,均在金融风控领域应用较广。
上述有监督学习分类算法往往需要在较大规模训练数据样本中,通过算法运算对数据样本情况进行归纳提炼,形成知识模型并实现智能应用;若模型训练数据样本积累不足(如创新业务领域“冷启动”状态),尤其在二分类任务中“1”“0”标签分布极度不平衡(如信用风险预测、欺诈识别场景等)的情形下,算法建模效果将大打折扣甚至完全失效。
基于关联规则挖掘的智能风控小样本学习
关联规则挖掘技术(Association Rule Mining)
关联规则挖掘问题由Agrawal等人于1993年提出:设I={i1, i2,..., im}为所有项目的集合,D为事务数据库,事务T是一个项目子集TI。每一个事务都具有唯一的事务标识T_ID。设A是一个由项目构成的集合,称为“项集”。事务T包含项集A,当且仅当AT。关联规则是形如X→Y的逻辑蕴含式,其中XI,TI,且X⌒Y=。如果事务数据库D中有S%的事务包含XY,则称关联规则X→Y的支持度为S%。若项集X的支持度为Support(X),规则的置信度为Support(XY)/Support(X),这是一个概率条件P(Y|X),也就是说:Support(X→Y)=P(XY),Confidence(X→Y)=P(Y|X)。为避免挖掘过程中产生过多不必要的规则,往往引入最小支持度min_sup和最小置信度min_conf这两个阈值。
关联规则挖掘分析能从大量数据中发现项集之间的相关和关联关系。关联规则挖掘任务分为两个步骤:一是频繁项集的产生,即找出满足最小支持度min_sup的所有项集,这些项集称作“频繁项集”;二是关联规则的产生,即从上一步发现的频繁项集中,提取所有高置信度的规则(满足min_conf条件),这些规则被称为关联规则。关联规则是形如X→Y的蕴含表达式,其中X和Y是不相交的项集,关联规则的强度可以用置信度和支持度度量。
基于关联规则挖掘的分类技术(Associative Classification)
在过往的认知中,关联规则挖掘是一种从大量数据中发现项集之间相关和关联关系的技术方法,最著名的应用场景是“啤酒尿片”购物篮分析。然而实际上,关联规则挖掘技术也可以用于解决有监督学习分类问题。该类思想最早由Ali等人于1997年提出;Wang等人于2007年提出针对此类关联规则的排序和加权方法,从而有效提升关联规则挖掘分类技术的模型准确性。基于关联规则挖掘技术开展有监督学习分类任务是挖掘形如{X1∪X2 ∪...∪Xm}→{Y0}的规则,其中Xi=1为特征标签值,Y0和Y1为类别标签。在金融风控领域,Y0和Y1类别标签可定义为“未逾期”和“逾期”。
基于关联规则挖掘分类技术的小样本学习创新技术方法
面向小样本学习技术创新,尤其当处理极度不平衡数据集时,本文将关联规则挖掘分类技术进行优化,探索形成一种可适用于产业数字金融风控问题(其训练数据样本量小、“坏”样本数据量极小)的关联规则挖掘分类技术方法,创新算法逻辑描述如下(见图1)。
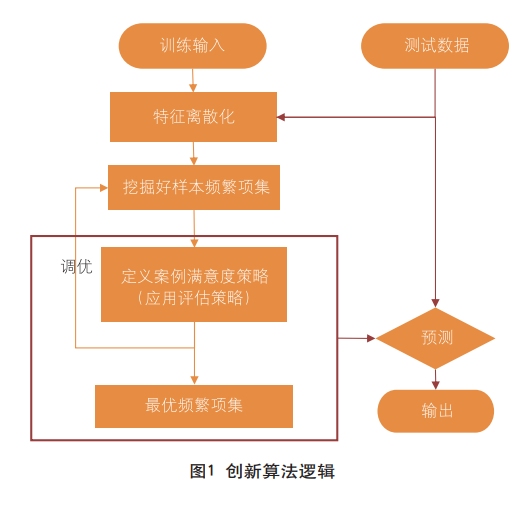
连续特征离散化。常规的频繁项集挖掘,往往是针对离散变量的,而数据中可能存在大量连续变量。针对连续变量,首先要采用等宽、等频或聚类等方式进行离散化处理,以便后续频繁项集挖掘任务的进行。
“好”样本频繁项集挖掘。完成连续变量分箱后,可针对“好”样本进行频繁项集的挖掘,这里的项集要满足以下条件:一是项集的支持度需比设定的min_sup阈值高,阈值依据模型评估结果动态调整;二是尽可能地挖掘出项次高的频繁项集,项次越高,频繁项集所包含的信息量也越大。
模型评估。筛选训练集部分“好”样本和全部“坏”样本进行逾期预测效果评估,评估策略的设置可包含以下情况:一是根据命中的频繁项集数目进行给定的数据样本评分,按评分排序后,评分小于K的定义为“坏”样本,否则为“好”样本;二是未命中任何频繁项集的定义为“坏”样本,否则为“好”样本。
模型稳定。评估此轮训练效果并调整min_sup和K值重新寻找频繁项集,直至模型稳定。
模型应用。将测试样本运用频繁项集和评估策略进行分类。
在商业银行产业数字金融业务领域的应用实践
以国内某商业银行产业数字金融业务为例,针对“加盟平台型”和“产业供应链型”两类典型业务,开展应用实践实证分析。该银行自2021年3月成立产业数字金融试点项目沙箱沙盒攻关组以来,逐步推进开展产业数字金融业务。在业务发展初期,项目的“好”“坏”样本数量欠缺积累,攻关组采用迁移学习思想并直接推进小样本学习技术创新,为平稳渡过和快速跨越业务“冷启动”期提供技术支撑。
从业务理解到数据准备
“加盟平台型”项目在借款人类型、贷款额度、还款期限等方面,与商业银行普惠金融业务相近,但具有明显的产业特征,主要体现为“产业圈”的商业模式。针对该类项目,攻关组从银行企业级数据仓库提取相关数据样本和特征构建宽表,开展数字化授信与智能风控算法建模数据准备工作:选取数据仓库近年来产品类型为个人经营性贷款且贷款额度为50万元以下、还款期限为3~6个月、贷款利率在8%以下的数据样本;定义逾期10天及以上为“坏”样本,“坏”样本在该选定数据集的占比为3%;以个人征信信息等典型A卡类特征作为初始变量筛选范围,排除缺失值和集中度过高及相关性较高的变量后,最终选取历史逾期类变量2个、历史额度类变量4个、时间和查询类变量4个,共计10个变量作为模型特征。
“产业供应链型”项目在借款人类型、贷款额度、还款期限等方面,与商业银行对公中小业务相近,但具有明显的产业特征,主要体现为“产业链”的商业模式。针对该类项目的风控算法建模数据准备包括:选取数据仓库近年来贷款额度在1000万元以下且还款期限1年以内、贷款利率在6%以下的对公贷款数据样本;定义逾期30天及以上为“坏”样本,“坏”样本在该选定数据集的占比为3%;选取“企业规模”等静态信息变量3个、“历史贷款平均额度”等历史行为记录变量6个,共计9个变量作为模型特征。
关于贷款利率范围的明确
在进行上述数据准备时,分别将“8%以下”“6%以下”作为贷款利率条件来选取“加盟平台型”和“产业供应链型”项目的风控模型训练与测试样本是因为在沙箱沙盒攻关过程中,将不同类型的每个产业数字金融项目看作一个进入沙盒的测试项目,并将真实发生的沙盒项目放入沙箱,由沙箱负责对全部项目开展统一的风险定价。该风险定价过程以项目为单位,通过对各项目的运营开展数字孪生,面向各类宏观因子变动下的风险情景,对银行资产负债管理体系进行相关仿真模拟,并推演出不同风险定价策略下银行未来经营收益情况;进而创新运用深度强化学习技术,以银行未来经营的最佳收益为目标,探寻覆盖沙箱内各沙盒项目的综合最优风险定价策略。这里“8%以下”和“6%以下”是根据沙箱给出的最优风险定价策略,对在数据样本中原本较为发散的贷款利率特征值进行适度聚向,使模型训练、测试以及预测应用的数据样本在贷款利率特征值范围上保持一致。
实证分析结果显示,将贷款利率特征值进行聚向处理,能够使模型准确性等模型评估指标(AUC、KS、Recall)得到明显提升。此外,精准的风险定价策略也对提升贷款质量和业务综合收益起到积极的促进作用。
建模与模型评估
经过前期的数据清洗、筛选等处理后,针对连续变量作分箱处理,以便后续开展频繁项集挖掘任务。模型训练前对原始样本数据划分训练集与测试集,训练集和测试集的划分采用分层随机抽样方法,即在“好”“坏”样本内分别随机抽样;为保证模型的稳定性,采取十次分层随机抽样的方式进行模型训练,并对十次随机分层抽样的平均结果进行分析及调优,最终在训练集样本量100、300、500(对应测试集样本量100、200、200)且“坏”样本占比保持在3%的情形下,得到模型测试集平均AUC、KS、Recall评估指标如表1、表2所示。
实证分析结果表明,本应用实践案例在科学有效的风险定价策略指导下,运用创新关联规则挖掘分类技术进行风控建模,无论是面对“加盟平台型”业务还是“产业供应链型”业务,均可在样本量很小(训练集样本量仅为100)且“坏”样本量极小(“坏”样本量占比仅为3%)的情况下,使模型具有良好的预测识别效果,在保持模型AUC、KS指标不低于0.7和0.3模型上线标准的前提下,使模型Recall指标平均达到0.8的水平,能够大幅提高相关业务的风控能力与工作效率。截至目前,该银行在产业数字金融一年以来的业务发展中未发生不良,即风险客户识别中非正常类样本Type-II错误率为零。
数字经济时代,面向产业数字金融风控领域的小样本学习问题成为商业银行亟待突破的技术难点之一。本文立足商业银行应用实践,在小样本学习领域运用关联规则挖掘分类算法进行创新技术突破,并将其实际应用于商业银行产业数字金融真实业务场景中,实证效果达到预期目标。后续,将进一步推进小样本学习技术面向训练集样本量在100以内的研究和应用,以期为数字经济时代商业银行深化产业数字金融业务发展提供技术支撑和借鉴思路。
(作者单位:华夏银行股份有限公司,龙盈智达〔北京〕科技有限公司,参与撰稿的有王彦博、赵勇江、张月、谭思颀、孙芳超、胡明珠、程义淇、徐奇、高新凯、杨璇、张军和刘曦子)
责任编辑:魏敏倩
公众号

微信扫码关注
微博

微博扫码关注